A data-driven view of the beacon chain incident
Prysm clients momentarily stopped proposing blocks, incurring limited delays and penalties but no loss of finalisation

On Friday, April 23rd, at epoch 32302 of the beacon chain, a bug affecting eth1 deposits took down the block producing abilities of most Prysm validator clients. The issue disappeared on its own during epoch 32320, before reappearing again the next day.
The short hiccups are worth dissecting to understand better how the beacon chain, a complex system driven by thousands of separate entities around the planet, behaves under and recovers from momentary lapses of reason. We'll see that even though its heart rate dropped significantly, the system was able to pump enough blood around to keep itself conscious throughout.
The efforts to find the bug are well-detailed in the Prysmatic Labs team post-mortem report, a recommended read for the full picture. To provide more background, this is the “Root cause” section of the report:
Eth2 is loosely coupled to the ETH1 chain, depending on it only for validator deposit verification. That is, the Eth2 proof-of-stake chain can continue even if validators are voting on junk data. The only thing that will fail is the onboarding of new validator deposits until the chain votes on the correct ETH1 data once again. This “voting” is done in “voting periods”, which are set to periods of 64 epochs on mainnet today (approximately 6.8 hours).
The way voting works is a simple majority rule, and the Eth2 specification for validators explains how this should work. Unfortunately, Prysm’s implementation of “voting with the majority” was missing some validation. What happened in the incident was a bug within Prysm led a block proposer to create a completely invalid ETH1 deposit tree root, and other Prysm nodes were the first to see it. Then, they would vote on it as Prysm was following a simple “voting with the majority” rule without explicit validation.
The effect of all Prysm nodes then “snowballing” into voting on the invalid information led to block proposers unable to include blocks with deposits in the chain, as the proposal would fail due to the deposits not verifying with respect to those nodes’ idea of the ETH1 deposit tree root. The incident resolved itself after the end of a voting period, but would continue to happen once more if left unanswered.
The actual root cause of the “corrupted” ETH1 data deposit tree root was due to a bug in the cache initialization for deposits affecting only a subset of beacon nodes using Prysm. This led those nodes to produce bad deposit tree roots, which then other Prysm nodes voted on, causing the incident.
In this post, I’ll look at three charts plotting the course and consequences of the client incident, drawing lessons on the behaviour of the protocol.
Prysm clients stop proposing
With a simple analysis on the graffiti included with beacon chain blocks, we can get a rough idea of the client software used by validators to build their blocks. By default, Lighthouse, Nimbus and Teku all include a graffiti string with their name and version. Prysm simply defaults to the empty string. We can also look up POAPs in case some validators still use those. This gives us the following picture:
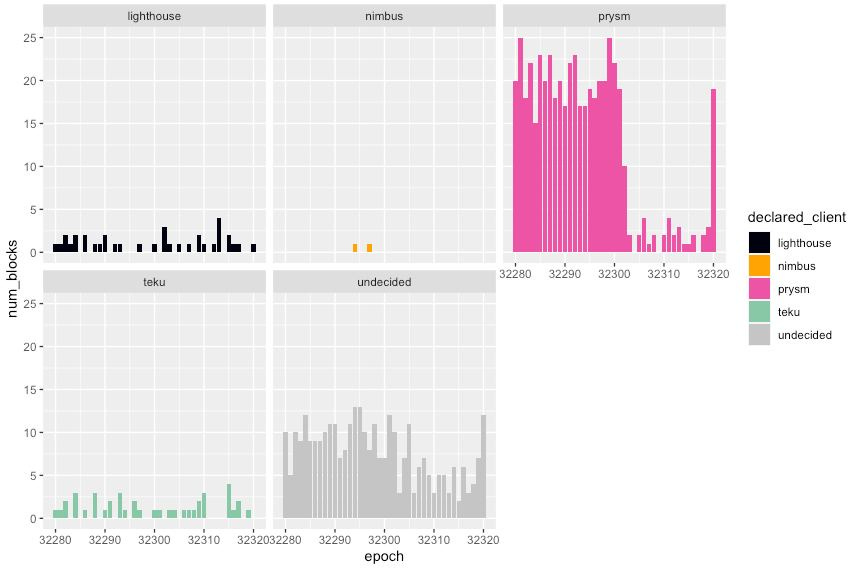
The column height indicates how many blocks each client proposed each epoch. Prysm is very much the dominant client on the network today, and it’s easy to observe the difference in blocks starting from epoch 32302, even among blocks that were tagged “undecided”. On beaconcha.in too we see blocks missing from this epoch onwards.

Delayed inclusion
On the beacon chain, validators are expected to produce votes indicating their view of the network, including the FFG source and target checkpoints as well as the current head of the chain, returned by the LMD-GHOST fork choice. Each validator is assigned one attestation slot per epoch, for which they are expected to produce an attestation. Once the attestation is broadcasted, it can be included at least one slot after the attestation slot, and at most 32 slots after.
In the figure below we plot the average inclusion delay of validators in red. This average tends to hover around 1: most blocks are proposed, so validators are included as soon as possible.
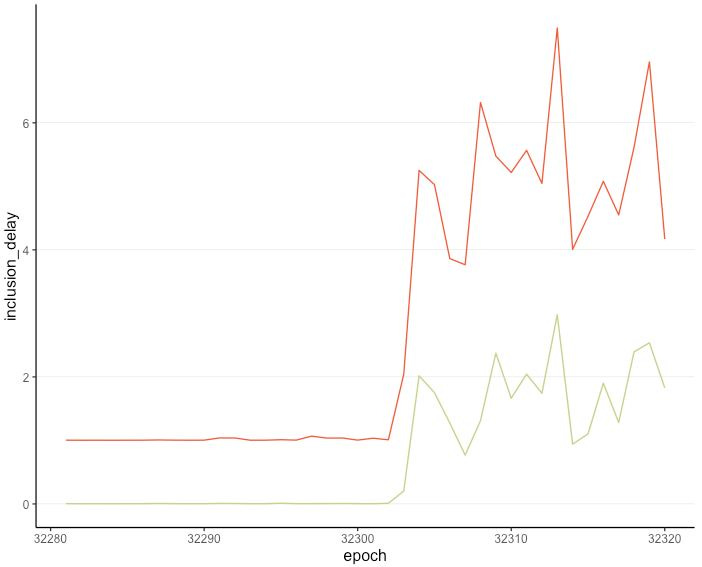
Past epoch 32302, the inclusion delay clearly increases, with validators needing to wait a longer amount of time for their attestations to be included.
One might ask: “Validators had to wait because blocks were unavailable, but once blocks were produced, were they included?” In green we plot the average minimal inclusion delay, where we count how long an attestation had to wait after a block was proposed. In general, this number is 0, since attestations are included as soon as a new block is available. After epoch 32302 though, this number significantly increased.
This is noteworthy since it could be the case that stranded attesting validators would get on the first available lifeboat (block) once that boat is ready to ship, but it’s not what happened. Instead, some validators had to wait several lifeboats before boarding and being included on-chain.
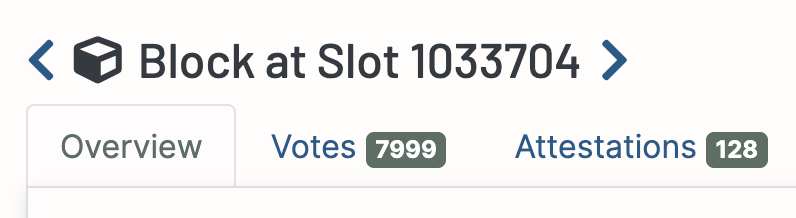
The block at slot 1033704 is one of the first blocks proposed during the incidents, coming after a series of 10 missed blocks in the slots prior. The block contains 128 aggregate attestations, the maximum a block can include. Each aggregate synthesises the votes of a slot committee, among which validators attesting for a slot are partitioned. There are now around 30 committees per attesting slot, so a block appearing after 3 missed blocks can barely include all aggregate attestations the 3 missed blocks were supposed to include (3 times 30, one per slot committee), plus its own (30 more). A block appearing after 10 missed slots has a lot of catching up to do.1 As a consequence, some validators reported missed attestations, having been unable to board before 32 slots went by.
Lost profits
As seen in the previous section, the chain was stressed, lifeboats were full, yet finalisation never stopped (the chain typically finalises as long as 2/3rds of the stake is online and included). This is excellent, and strong evidence for the robustness of the protocol. Yet block proposers who were affected by the incident lost block proposing rewards, which are a significant, if infrequent, share of validator rewards. Online validators who could not get on a lifeboat in time also lost a small share of rewards.
We can get a better idea of the loss incurred by looking at the net difference in balances between each epoch during the incident. We only chart it for the first occurrence here.
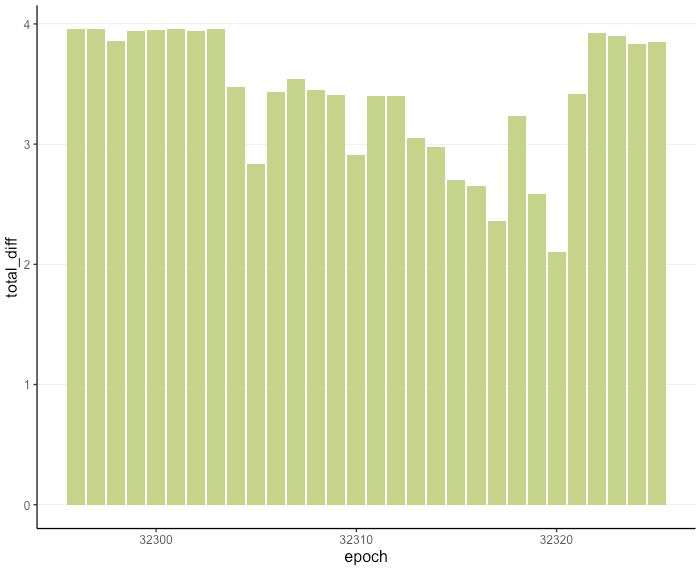
The height of the column indicates the net profit earned by all validators at the end of each epoch. The protocol either mints rewards for validators who performed their duties and were included, or decreases the balance of validators who failed at either. Adding up these rewards and losses we obtain the chart above.
The white area between epoch 32302 and 32320 gives us a rough idea of the profit loss by validators. It is hard to get a fully precise number: we ought to know which validators were online and validating but were unsuccessful at being included to write down the loss as caused by the incident. So taking the few epochs net profit prior to epoch 32302 yields a baseline of around 3.93 ETH per epoch. Summing up the differences between this baseline and the realised net profit between epochs 32302 and 32320, we get a good estimation of the loss, which adds up to around 15.9 ETH, or around $40,000 at $2,500 ETH/USD.2
Closing thoughts
Major credits go towards the work of the Prysmatic Labs team and researchers who tracked down the issue and fixed it in a timely manner. Fortunately, finalisation continuing despite the reduced number of produced blocks prevented the quadratic inactivity leak, which incurs more severe penalties on validators failing to be included.
Yet it’s also important to recognise limits of the protocol. As we’ve seen, each slot provides the opportunity for 128 aggregate attestations to be included, and we have 32 slots per epoch, so 4096 opportunities to include aggregates per epoch. If a fraction f of blocks is missing, we are reduced to 4096 * (1-f ) opportunities. Since each slot committee targets a membership of 128 validators, for N currently active validators we have ~N/128 committees per epoch, who must fit within 4096 * (1-f ) opportunities. With the current numbers, we are running out of opportunities as soon as over f = 75% of blocks are missing. With Prysm’s dominance among validator clients, we got close to this number during the incidents, and sometimes even above, so some attestations were left behind.
At the risk of repeating an oft-heard refrain, client diversity matters. All of the four major eth2 clients have produced excellent infrastructure, and it’s worth giving a shot to another one of them if you haven’t yet.3 Check out for instance Michael Sproul’s guide to setting up Lighthouse, read about Nimbus's latest optimisations from Jacek Sieka or Teku’s Ben Edgington’s own take on client diversity. Their respective Discords and the folks at EthStaker are also here to help!
Many thanks to Danny Ryan for comments. All code used to obtain the data and plots available here.
Subscribe to this (infrequent) newsletter to read more about Ethereum, incentives and in-depth analysis
See also my previous piece on Exploring the first 1000 epochs of eth2 for more details on aggregation
I have not tallied up the loss for the second incident, but the post-mortem mentions a smaller figure for it (~$0.22 per validator)
I’ve tested all four clients during initial and later testnets, if that’s worth anything. This beacon can fit so many clients!
Soy un usuario novato en estos aspectos , pero debo agradecerte por tu contenido de muy buena calidad , muchas gracias